Claude Code Skills로 알고리즘 풀이 환경 다듬기
들어가며
이전 글에서 CLAUDE.md에 문제 준비 플로우와 풀이 후 플로우를 정의해서 Claude Code와 함께 쓰는 환경을 만들었다. 꽤 만족스럽게 쓰기는 했는데, 쓰다 보니 슬슬 불편한 점이 눈에 띄기 시작했다.
가장 불편했던 건 암묵적 트리거였다. CLAUDE.md에 "사용자가 문제 링크를 제공하면 아래 순서로 진행한다"처럼 적어두는 방식으로 클로드의 동작을 트리거했는데, 의도하지 않은 타이밍에 플로우가 실행되거나 아니면 의도한 플로우를 빼먹는 경우도 있었다. 그리고 md 파일이 252줄까지 불어나면서 사람이 읽기도 어려워졌다.
마침 Claude Code에 Skills 라는 기능이 있다는 걸 알게 됐고, 공부하다 보니 내 니즈를 아주 잘 채워 줄 수 있을 것 같아서 이 기회에 워크플로우 전체를 Skills로 분리해보기로 했다.
Skills 시스템 탐구
Skills는 .claude/skills/<skill-name>/SKILL.md 형태로 저장하는 커스텀 command이다. /prep, /done처럼 명시적으로 호출하는 방식이라 내가 불편하게 생각했던 암묵적 트리거 문제가 깔끔하게 해결된다. /를 입력하면 등록된 skill 목록이 자동완성으로 쭉 뜬다.
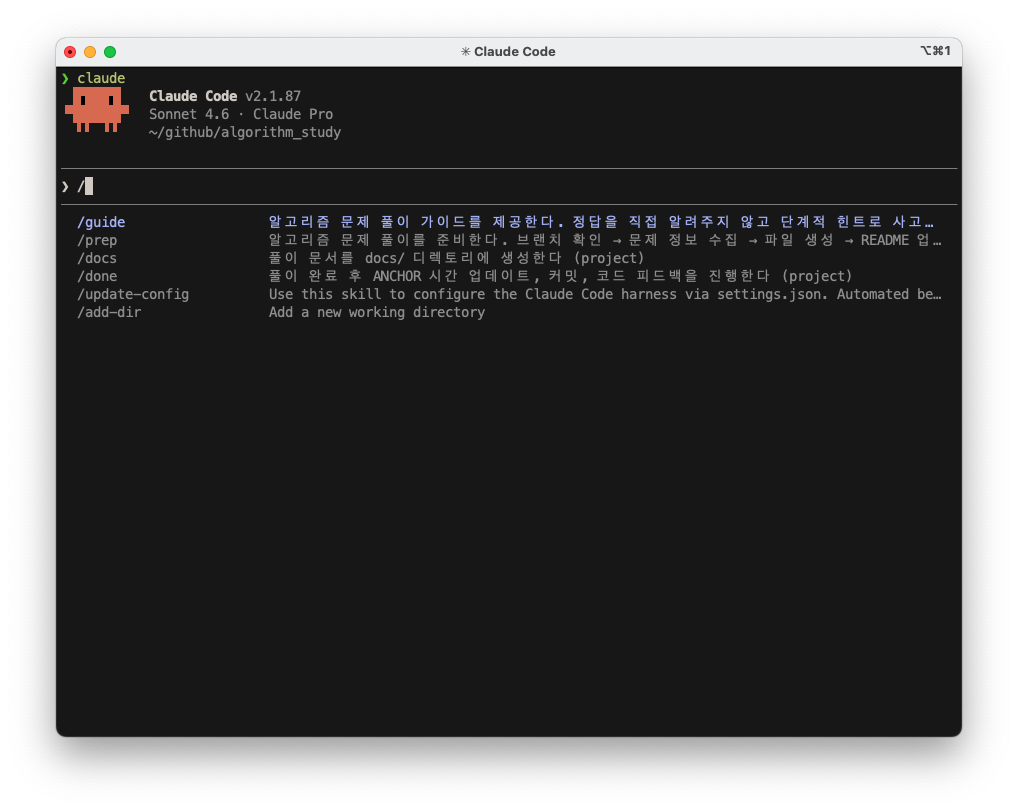
이렇게 argument-hint 필드를 설정하면 인자가 필요한 커맨드에 placeholder도 표시된다.
---name: prepargument-hint: "<url> [language]"---
스킬 디렉토리 하나의 구조는 이렇게 생겼다. (참고)
my-skill/├── SKILL.md # 필수 - 워크플로우 흐름├── reference.md # 선택 - 상세 규칙/스펙 (필요할 때만 로드)├── examples.md # 선택 - 구체적인 예시 (필요할 때만 로드)└── scripts/└── helper.sh # 선택 - 실행 스크립트
Skill을 쓰면 좋은 이유는 로드 방식에 차이가 있기 때문이다. CLAUDE.md는 매 대화마다 전체가 컨텍스트에 올라오는 반면, Skills는 프론트매터의 name과 description만 먼저 로드되고, SKILL.md 본문과 reference.md, examples.md 같은 supporting files는 해당 skill이 실제로 호출될 때만 로드된다.
즉 /prep을 호출하지 않는 대화에서는 파일명 규칙, 헤더 형식, README 테이블 형식 등이 컨텍스트에 전혀 올라오지 않는다. 이런 상세 컨벤션들을 CLAUDE.md에 두는 건 사실 낭비였던 것이다.
따라서 description 필드를 잘 작성하는 것도 중요하다. 이 스킬들은 명시적으로 호출할 수도 있지만 Claude가 문맥으로 판단해서 호출하기도 한다. 그때 Claude가 skill 목록에서 보는 건 name과 description뿐이라, 어떤 skill을 언제 써야 하는지 판단하는 근거가 여기서 나오기 때문이다. 각 skill의 description은 사람도 읽기 좋고 Claude도 읽기 좋게 명료한 한국어로 작성했다.
---name: prepdescription: 알고리즘 문제 풀이를 준비한다. 브랜치 확인 → 문제 정보 수집 → 파일 생성 → README 업데이트---
---name: guidedescription: 알고리즘 문제 풀이 가이드를 제공한다. 정답을 직접 알려주지 않고 단계적 힌트로 사고를 유도한다---
---name: donedescription: 풀이 완료 후 ANCHOR 시간 업데이트, 커밋, 코드 피드백을 진행한다---
---name: docsdescription: 풀이 문서를 docs/ 디렉토리에 생성한다---
---name: prdescription: 오늘 푼 문제들로 PR을 생성한다---
---name: mergedescription: 현재 브랜치의 PR을 rebase 머지하고 main으로 돌아온다---
또 하나 유용했던 건 !`command` 문법이다. SKILL.md 안에서 쉘 명령어를 실행해서 결과를 프롬프트에 직접 주입할 수 있다. Claude가 SKILL.md를 읽는 순간 명령어가 먼저 실행되고, 결과가 삽입된 채로 프롬프트가 전달된다.
브랜치 상태: !`bash .claude/skills/prep/scripts/branch-check.sh`
allowed-tools 필드로 skill 실행 중 Claude가 사용할 수 있는 tool을 제한할 수도 있다. 전체 Bash 접근을 열어주는 대신, 허용할 명령어를 명시적으로 지정하는 방식이다.
allowed-tools: Bash(bash .claude/skills/prep/scripts/*), mcp__algorithm__get_leetcode_problem, mcp__algorithm__get_backjoon_problem
workflow → skills 분리
총 6개의 skill을 만들었다.
| 커맨드 | 설명 |
|---|---|
/prep <url> | 브랜치 확인 → 문제 수집 → 파일 생성 → README 업데이트 |
/done | ANCHOR 업데이트 → 커밋 → 코드 피드백 |
/docs | 풀이 문서 생성 |
/pr | PR 생성 |
/merge | PR rebase 머지 |
/guide | 단계적 힌트 제공 |
/docs는 원래 /done 안에 묶여 있었는데 따로 분리했다. 피드백을 받고 나서 코드를 수정하는 경우가 있어서, 최종 코드가 확정된 후에 명시적으로 호출하는 게 더 자연스럽다고 판단했다.
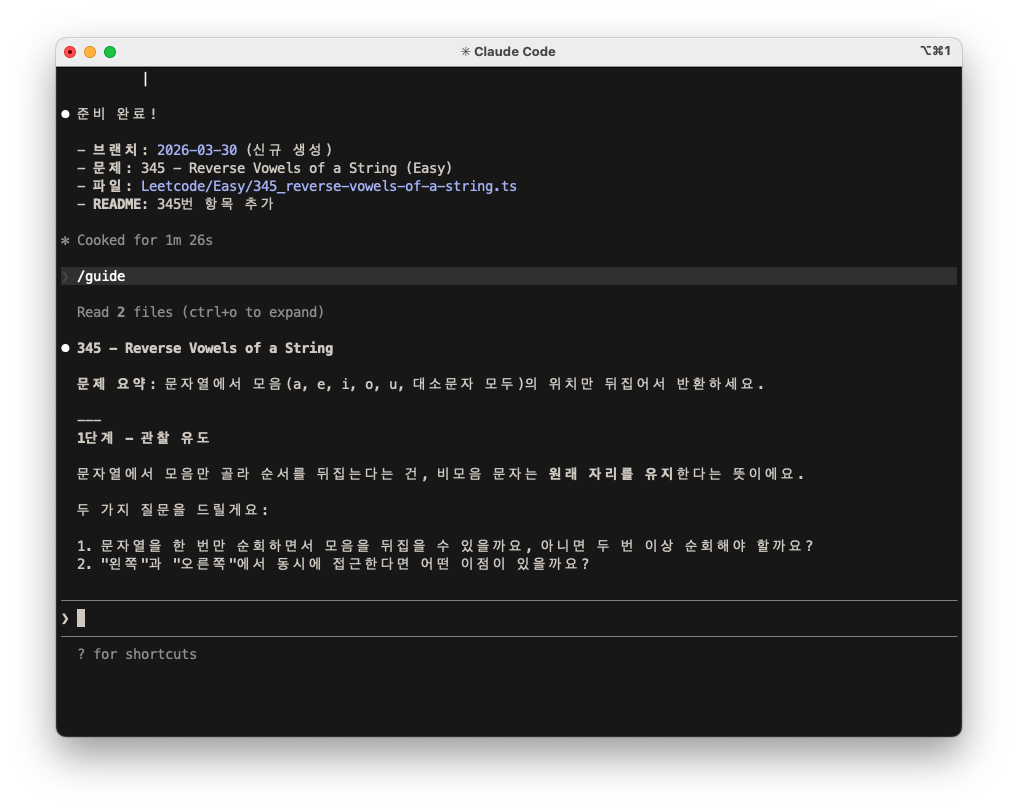
/guide
단계적 힌트를 제공하는 skill이다. 정답을 직접 알려주지 않고, 막힌 정도에 따라 힌트 단계를 높여간다. (힌트 단계 구분은 역시 클로드의 도움을 받았다.)
- 관찰 유도 : 문제에서 주목할 패턴을 질문으로 제시
- 접근법 힌트 : 알고리즘 유형이나 자료구조만 언급
- 접근 방향 제시 : 풀이 흐름을 단계별로 설명 (코드 없이)
- 의사코드 : 실제 코드 없이 로직 구조만 제시
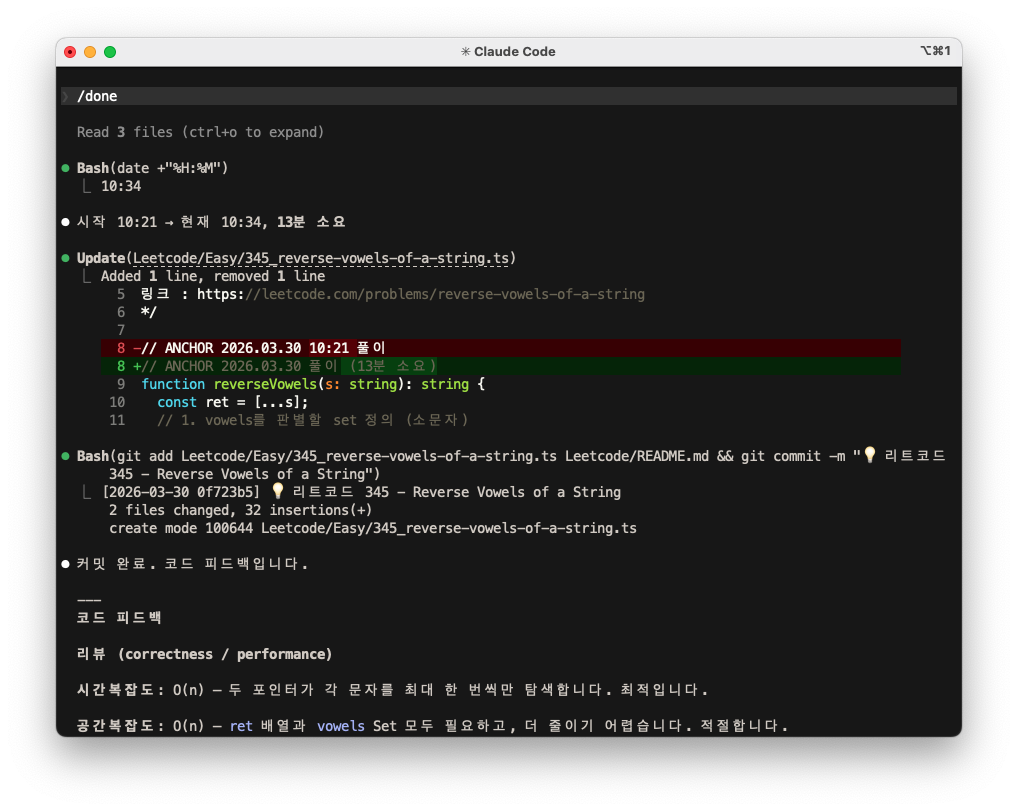
/done
ANCHOR 주석에서 풀이 시작 시간을 읽어 풀이 소요 시간을 계산하고, 커밋 후 코드 피드백까지 한 번에 진행한다.
/docs
풀이 코드를 읽어 docs/ 디렉토리에 문서를 생성한다. 단순해 보이지만 신경 쓸 부분이 많았다.
처음에는 git log -1 --name-only처럼 가장 최근 커밋 기준으로 문서를 만들 풀이 파일을 찾도록 했었는데, 이렇게 하니 호출 타이밍에 따라 다른 결과가 나올 수도 있었다. /docs는 /done 직후에 바로 실행하지 않을 수도 있고, 하루에 여러 번 호출될 수도 있다. 이 경우 "오늘 풀이한 파일이 뭔지", 그리고 "오늘 풀이했지만 문서를 만들지 않은 파일이 뭔지"를 정확히 알아야 했다.
그래서 git diff main...HEAD --name-status를 사용한다. 현재 브랜치 전체 기준이라 실행 타이밍에 무관하게 오늘 풀이한 파일을 모두 가져온다. --name-status로 A(신규)/M(수정) 상태도 함께 확인해서, 파일별로 처리 방식을 다르게 했다. SKILL.md에서는 !`git diff main...HEAD --name-status`로 결과를 프롬프트에 주입한다.
<!-- docs/SKILL.md -->## 풀이 파일 확인 방법현재 브랜치에서 main과 달라진 파일 목록: !`git diff main...HEAD --name-status`위 목록에서 풀이 코드 파일(Baekjoon/, Programmers/, Leetcode/ 경로)을 찾아 기준으로 한다.
- A (신규 풀이): docs 파일 존재 여부만 확인한다. 있으면 이미 처리된 것으로 보고 건너뜀, 없으면 생성.
- M (재풀이): docs 파일이 없으면 생성. 있으면 내용을 읽어 오늘 날짜 섹션(
## 풀이 2 (2026-03-30))이 있는지 확인하고, 없으면 추가한다.
오늘 생성한 파일을 별도의 파일로 캐싱해두는 방법을 생각하기도 했는데, A 파일은 파일 존재 여부만 확인하면 되므로 내용을 읽을 필요가 없다. 하루에 재풀이가 여러 개인 경우는 드물어서, 실제로 내용까지 읽어야 하는 파일이 많지 않을 것이라 판단해 내용을 직접 읽도록 했다. 재풀이 섹션 헤더에 날짜를 포함하는 건 중복 처리 방지 외에도, 언제 재풀이했는지가 문서에 남는다는 점에서도 유용했다.
supporting files로 컨벤션 위임
CLAUDE.md에 있던 상세 컨벤션들은 각 skill의 supporting files로 분산시켰다. reference.md는 규칙과 형식, examples.md는 구체적인 예시를 담는다.
prep/reference.md: 파일명 규칙, 언어 설정, 헤더 형식, README 테이블 형식prep/examples.md: 파일 헤더 예시, README 테이블 예시done/reference.md: ANCHOR 형식, 커밋 메시지 형식, 코드 피드백 기준done/examples.md: ANCHOR 변환 예시, 커밋 메시지 예시docs/reference.md: docs 템플릿, 태그 규칙guide/reference.md: 단계적 힌트 체계
SKILL.md는 흐름만 담고, 상세 규칙과 예시는 필요할 때만 로드되는 구조가 됐다.
그런데 실제로 사용해보니 컨텍스트 스위칭이라고 해야 할까? Skill 문서를 읽다가 supporting file을 읽으러 가는 시간이 추가되면서 전반적인 작업 속도가 좀 줄어든 것 같은 느낌이 들기도 했다. 이 부분은 다른 활용 사례들도 찾아보면서 개선할 방법이 있을지 확인해 볼 생각이다.
scripts/ 활용
/prep의 브랜치 확인 로직은 scripts/branch-check.sh로 분리했다.
#!/bin/bashlast=$(git --no-pager log --format="%cd" --date=format:"%Y-%m-%d" -1)today=$(date +%Y-%m-%d)echo "last=$last today=$today"
SKILL.md에서는 !`bash .claude/skills/prep/scripts/branch-check.sh`로 호출하면, Claude가 직접 git 명령을 실행하는 대신 스크립트 결과(last=2026-03-29 today=2026-03-30)를 보고 브랜치 생성/이동 여부를 판단한다.
Subagents 탐구
Skills를 정리하다 보니 Subagents라는 기능도 눈에 들어왔다. Subagent는 특정 작업에 특화되어 독립적인 컨텍스트에서 실행되는 에이전트이다. context: fork를 skill frontmatter에 추가하면 해당 skill을 격리된 환경에서 실행할 수 있다. (물론 스킬과 별개로 subagent를 정의할 수도 있다.)
처음엔 /guide, /prep, /docs 모두 후보였는데, 공식 문서에 나와 있는 판단 기준을 참고해서 실제 적용할 스킬을 결정했다.
격리된 subagent 컨텍스트가 아닌 주 대화 컨텍스트에서 실행되는 재사용 가능한 프롬프트 또는 워크플로우를 원할 때 Skills를 대신 고려합니다.
이 기준을 적용하면:
/guide: 힌트를 받고 질문하고 더 받는 게 핵심. 격리된 상태가 아닌 실제로 사용자와 대화가 필요하기 때문에 탈락./prep: Programmers는 난이도를 사용자에게 물어봐야 하는 단계가 있고, 브랜치 확인 → 파일 생성 → README 업데이트가 순차적으로 컨텍스트를 공유하기 때문에 탈락./docs: 코드 읽고 파일 생성. 사용자와는 별개로 완전히 독립된 작업이기 때문에 적합.
결국 /docs에만 Subagent를 적용했다. docs-writer라는 agent를 만들고, skill에서 연결했다.
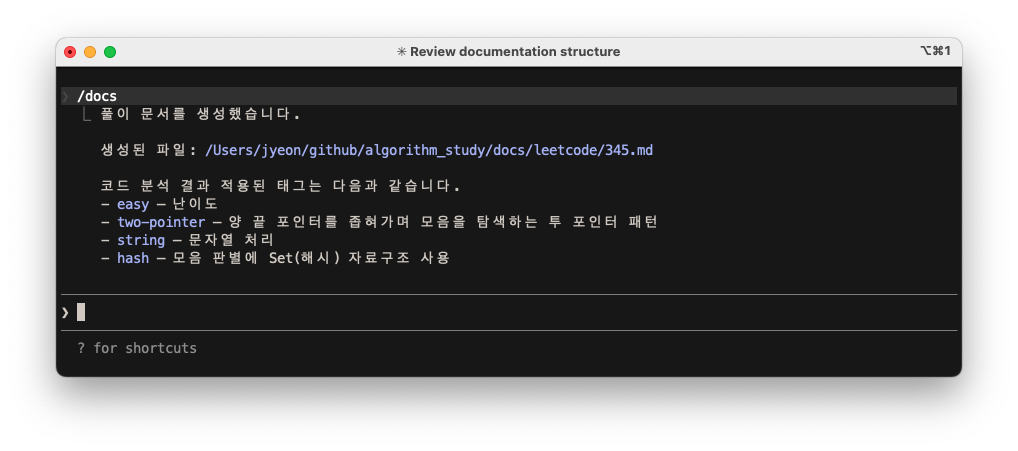
이렇게 파일 생성 과정은 다른 컨텍스트에서 실행되고, 사용자에게는 결과 요약만 보여준다.
<!-- docs/SKILL.md -->---name: docscontext: forkagent: docs-writer---
<!-- docs-writer.md -->---name: docs-writertools: Read, Write---`/docs` skill의 subagent로, 알고리즘 풀이 코드를 읽고 docs/ 디렉토리에 풀이 문서를 생성한다.
앞서 SKILL.md에 등장했던 allowed-tools는 메인 컨텍스트 skill에만 유효하고 subagent가 쓸 수 있는 tool은 agent 정의 파일에서 결정된다. 그래서 git 명령어 결과가 필요한 경우 allowed-tools: Bash(...)가 아닌 ! 프리픽스로 SKILL.md 로드 시점에 결과를 프롬프트에 주입하는 방식을 썼다. subagent가 시작되기 전에 실행되므로, Bash 없이도 결과를 받을 수 있다.
docs-writer agent를 만들기는 했지만, 상세한 skill에 대한 제약사항들은 모두 agent가 아닌 skills에 뒀다. 내 경우에는 내용 섹션을 임의로 채우지 않는 것, 풀이 코드를 수정하지 않는 것이라는 제약사항을 추가해야 했는데, 모두 agent보다는 작업과 더 연관된 제약사항이라고 생각했기 때문이다.
결과
CLAUDE.md가 252줄 → 30줄로 줄었다.
# Algorithm Study Repository Guide## 저장소 구조...## Skills/prep <url> → 풀이 → /done → /docs → /pr → /merge...
항상 로드되는 내용은 저장소 구조와 skill 목록뿐이고, 나머지 상세 컨벤션들은 각 skill이 호출될 때만 올라온다. 최종 디렉토리 구조는 이렇게 됐다.
.claude/├── agents/│ └── docs-writer.md└── skills/├── prep/│ ├── SKILL.md│ ├── reference.md│ ├── examples.md│ └── scripts/│ └── branch-check.sh├── done/│ ├── SKILL.md│ ├── reference.md│ └── examples.md├── docs/│ ├── SKILL.md│ └── reference.md├── guide/│ ├── SKILL.md│ └── reference.md├── pr/│ └── SKILL.md└── merge/└── SKILL.md
끝
기존 환경에서 묘하게 불편했던 부분을 skill이라는 것으로 깔끔하게 해결할 수 있어서 너무 너무! 만족스럽다. 약간 코딩 처음 배웠을 때의 느낌이랑 비슷한 감정인 것 같다. 이렇게 하는 방법이 있었다니! 이번 작업에서 특히 좋았던 점은 단순히 동작하게 만드는 것보다 어떤 구조를 선택해야 하는지 고민할 수 있는 지점이 많았다는 점이다. Skill은 어떤 구조로 나눌지, Subagent를 어디에 쓸지, agent가 skill을 사용하는 방향으로 할지, 아니면 skill을 agent로 실행하는 방향으로 할지, 풀이 문서는 어떤 기준으로 생성할 것인지 같은 것들을 따져보는 과정이 너무너무 재밌었다!!
그리고 저번에는 공부하기 싫어서 방정리하는 느낌이라고 했었는데, 실제로 이렇게 환경을 구성해두고 나서 꽤 일정한 시간에 꾸준히 문제를 풀 수 있었다. 예전에는 예상했던 것보다 시간이 많이 걸려서 오전에 알고리즘 문제를 푼다는 루틴을 지키지 못하거나 미루곤 했었다. 하지만 요즘은 그냥 문제만 풀고 생각 정리만 잘 하면 되어서 부담 없이 시작해서 빠르게 마무리한다. 알고리즘 풀이하기를 일상 루틴에 녹이기에 성공한 것 같다... 🥹 앞으로 또 어떤 불편함이 나를 거슬리게 만들지 기대된다. 재밌겠다!